Yuehao Huang
Ph.D. Student @ April Lab, Zhejiang University

I am currently pursuing my Ph.D. degree at the College of Control Science and Engineering at Zhejiang University since 2023, where I work in the April Lab under the supervision of Prof. Yong Liu. Alongside my doctoral studies, I am a research intern at the Institute of Artificial Intelligence of China Telecom (TeleAI). Prior to this, I received my B.Eng. degree in Intelligence Science and Technology from Hangzhou Dianzi University in 2023 under the guidance of Prof. Qiuxuan Wu.
Research Interests
The following are my current research interests:
- Embodied Navigation
- Autonomous Driving
- AIGC
news
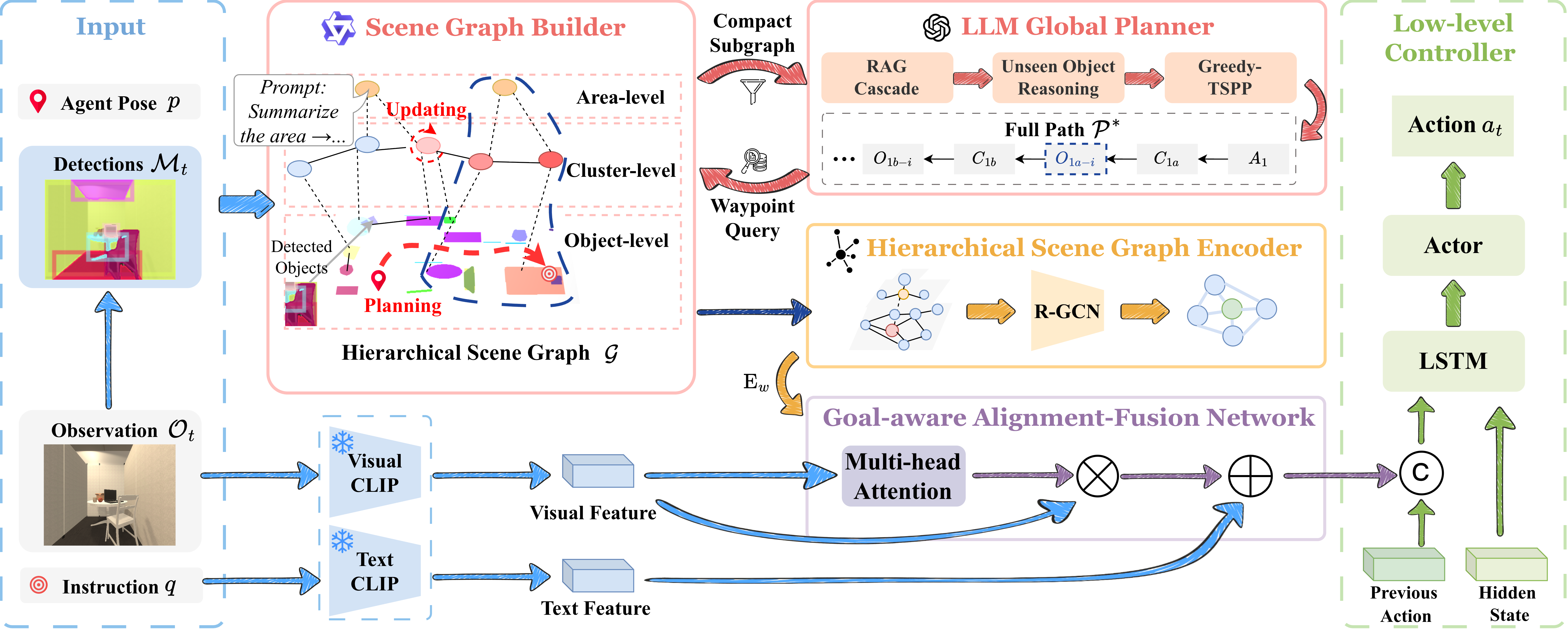
| Jun 17, 2026 | 🎉 Paper SAGE-Nav: Leveraging LLM Planning and Alignment Fusion for Hierarchical Scene Graph-Guided Navigation is accepted by IROS 2026 ! |
|---|---|
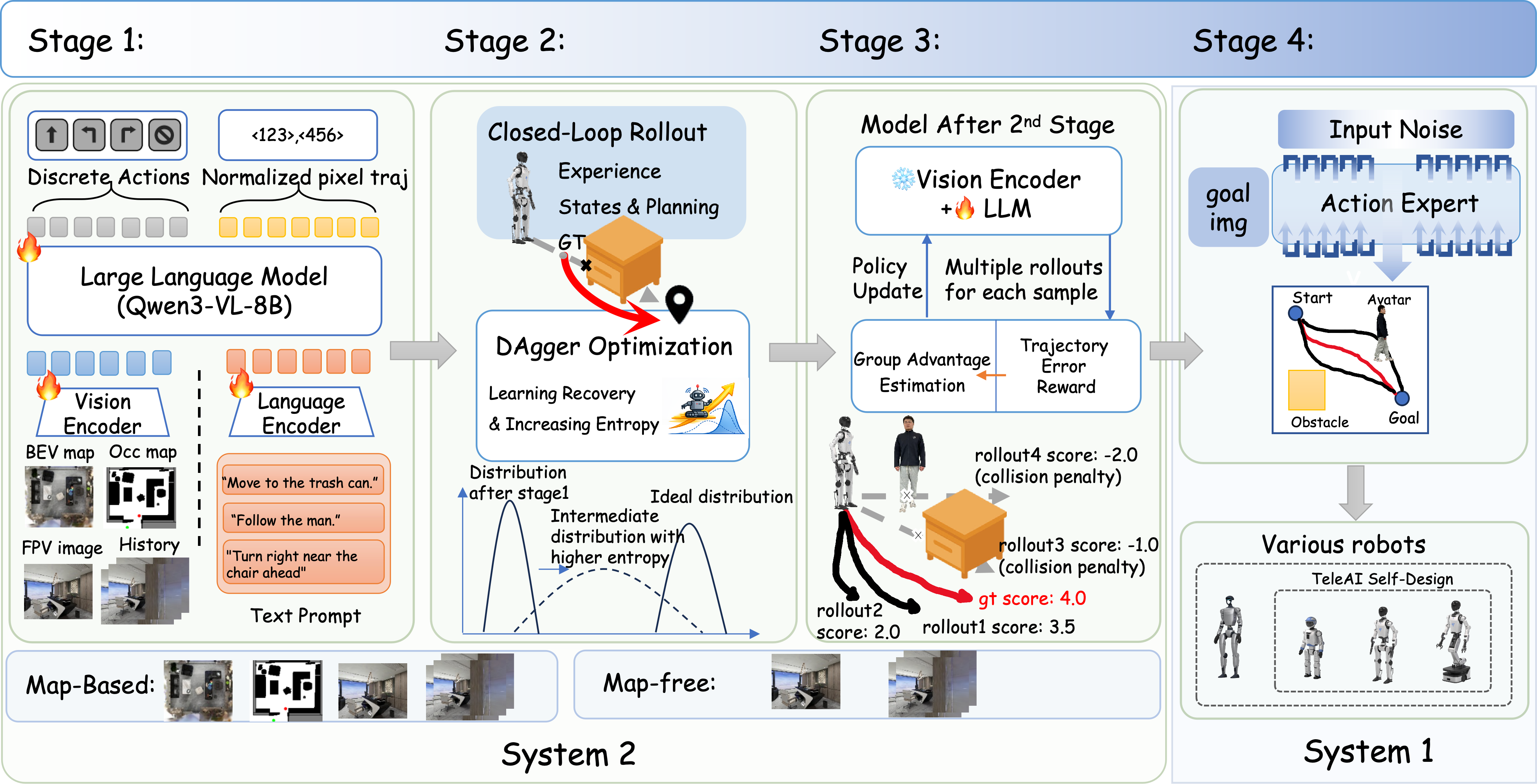
| Feb 21, 2026 | 🎉 Paper Drive-Cascade: Autoregressive Occupancy to LiDAR and Video Synthesis is accepted by CVPR findings 2026 ! |
| Dec 07, 2025 | 🏆 Thrilled to share that our team from APRIL Lab won the Championship at the ATEC 2025 Technology Elite Competition ! |
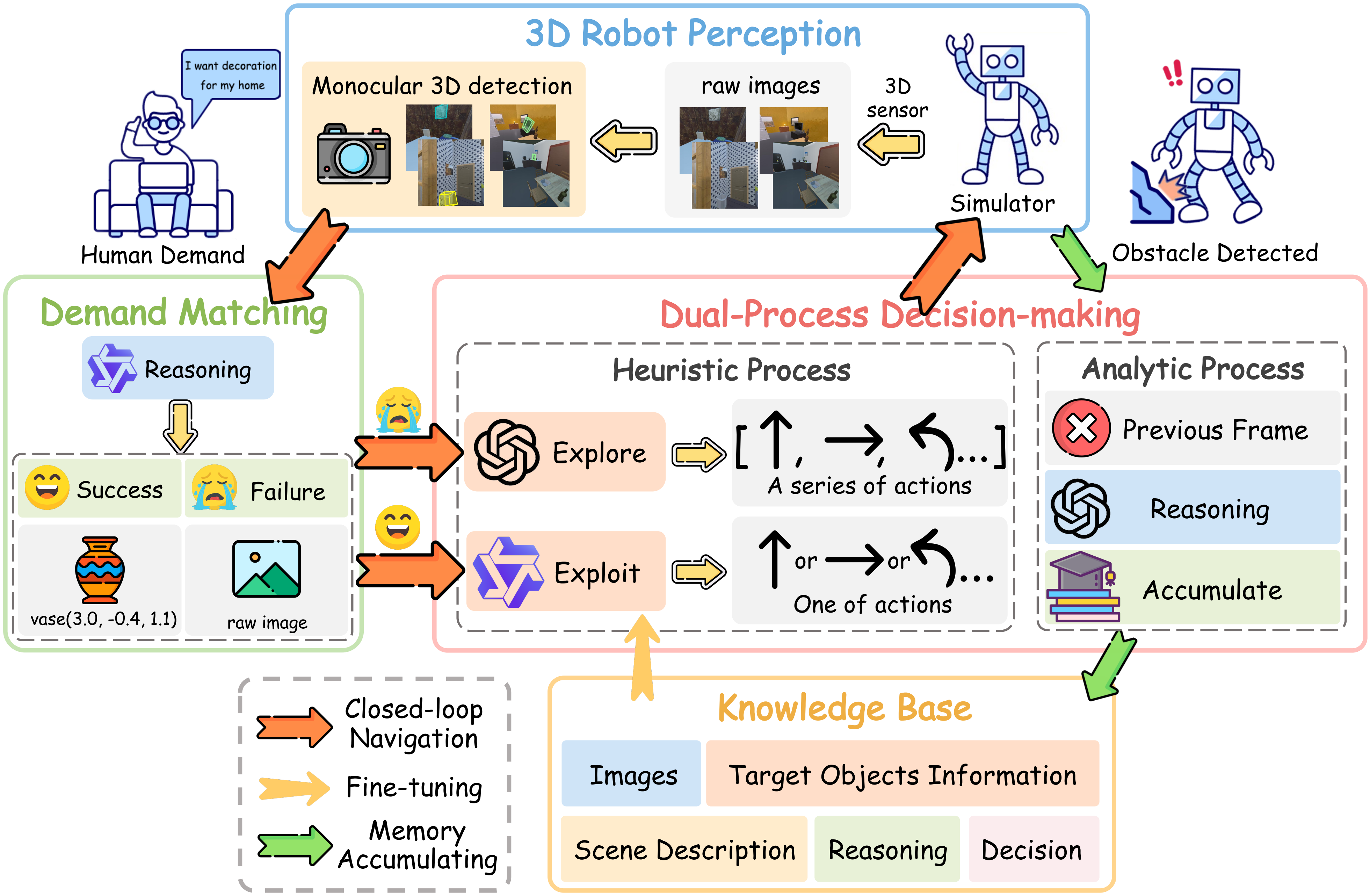
| Jul 05, 2025 | 🎉 Paper CogDDN: A Cognitive Demand-Driven Navigation with Decision Optimization and Dual-Process Thinking is accepted by MM 2025 ! |